
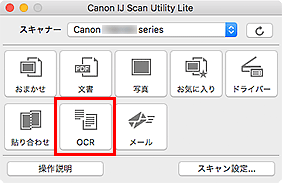
スキャンした画像から文字列を抜き出す(OCR)
IJ Scan Utility Lite基本画面で[OCR]をクリックすると、画像としてスキャンした雑誌や新聞などの活字を、ワープロソフトなどで編集可能なテキスト(文字)データに変換することができます。
![]() 参考
参考
- [文書]、[お気に入り]、または[ドライバー]からも、文字列を抜き出すことができます。
-
[スキャン設定...]をクリックし、[スキャン設定(OCR)]ダイアログで、原稿の種類や解像度などを設定し、結果を表示させたいアプリケーションソフトを選択
設定が完了したら[OK]をクリックしてください。
 参考
参考- [解像度]は、[300dpi]または[400dpi]のみを設定できます。
- 対応するアプリケーションソフトがインストールされていない場合は、画像内の文字列を抽出し、ご使用のテキストエディタに表示します。
表示される文字列は、[スキャン設定(基本設定)]ダイアログの[文書の言語]を基準としています。[文書の言語]で、抽出したい言語を選んでからスキャンしてください。 - ポップアップメニューからアプリケーションソフトを追加することもできます。
-
原稿台に原稿をセット
-
[OCR]をクリック
スキャンが開始されます。
スキャン終了後、設定した内容でスキャン画像が保存され、指定したアプリケーションソフトに抜き出された文字列が表示されます。
参考- スキャンを中止したいときは、[キャンセル]をクリックしてください。
-
ご使用のテキストエディタに表示される文字列は簡易的なものであり、次のような原稿は、画像内の文字を正しく認識できない場合があります。
- 文字サイズが8ポイント~40ポイント(300 dpi時)の範囲外の文字を含む原稿
- 傾いた原稿
- 上下が逆になっている原稿や文字が横になっているなど、文字の方向が正しくない原稿
- 特殊なフォント、飾り文字、斜体(イタリック)、手書きの文字を含む原稿
- 文字の行間が狭い原稿
- 文字の背景に色がついた原稿
- 複数の言語を含む原稿
