
Extracting Text from Images (OCR Function)
Scan text in images and display it in Notepad (included with Windows).
![]() Important
Important
- PDF files cannot be converted to text.
- Text conversion may not be possible depending on the size of the selected image.
-
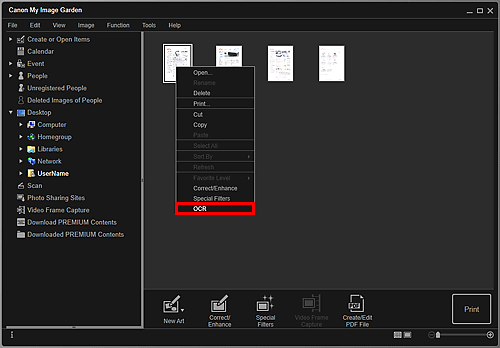
Display the image you want to convert into text.
-
Right-click the image you want to convert into text, then click OCR from the displayed menu.
Notepad (included with Windows) starts and editable text appears.
 Note
Note- Only text written in languages that can be selected in the Advanced Settings tab of the Preferences dialog box can be extracted to Notepad (included with Windows). Click Settings... on the Advanced Settings tab and specify the language according to the language of the document to be scanned.
When scanning multiple documents, you can collect the extracted text into one file. -
Text displayed in Notepad (included with Windows) is for guidance only. Text in the image of the following types of documents may not be detected correctly.
- Documents containing text with font size outside the range of 8 points to 40 points (at 300 dpi)
- Slanted documents
- Documents placed upside down or documents with text in the wrong orientation (rotated characters)
- Documents containing special fonts, effects, italics, or hand-written text
- Documents with narrow line spacing
- Documents with colors in the background of text
- Documents containing multiple languages
- Only text written in languages that can be selected in the Advanced Settings tab of the Preferences dialog box can be extracted to Notepad (included with Windows). Click Settings... on the Advanced Settings tab and specify the language according to the language of the document to be scanned.
