Сканирайте текста в изображенията и го отворете с Notepad (включен в Windows).
 Важно
ВажноPDF файлове не могат да се конвертират в текст.
Конвертирането на текст може да не е възможно в зависимост от размера на избраното изображение.
Изведете изображението, което искате да преобърнете в текст.
Щракнете с десен бутон върху изображението, което искате да превърнете в текст, след което щракнете върху опцията OCR в изведеното меню.
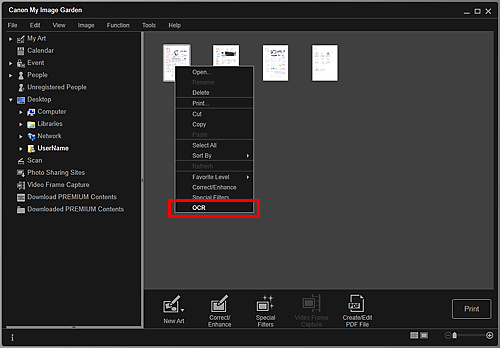
Notepad (включен в Windows) ще се стартира и ще се покаже текст, който може да се редактира.
 Забележка
ЗабележкаСамо текстове, написани на езици, които могат да се изберат от раздела Разширени настройки (Advanced Settings) на диалоговия прозорец Предпочитания (Preferences), могат да се извлекат в Notepad (включен в Windows). Щракнете върху Настройки... (Settings...) в раздела Разширени настройки (Advanced Settings) и укажете език, отговарящ на езика на документа, който ще сканирате.
Когато сканирате няколко документа, можете да съберете извлечения текст в един файл.
Текстът, показан в Notepad (включен в Windows), е само за указание. Текстът в изображения от следните типове документи не може да се разпознае правилно.
Документи, съдържащи текст с размер на шрифта извън границите от 8 до 40 пункта (при 300 dpi)
Наклонени документи
Документи, поставени надолу с главата или документи с текст в грешна ориентация (завъртяни знаци)
Документи, съдържащи специални шрифтове, ефекти, курсив или ръкописен текст
Документи с тясна редова разредка
Документи с цветен фон зад текста
Документи, съдържащи няколко езика
Начало на страницата |