
Extracción de texto de imágenes escaneadas (Función OCR)
Escanee el texto en imágenes y muéstrelo en TextEdit (incluido en Mac OS).
![]() Importante
Importante
- Los archivos PDF no se pueden convertir en texto.
- La conversión de texto puede que no sea posible dependiendo del tamaño de la imagen seleccionada.
-
Acceda a la imagen que desea convertir en texto.
-
Haga clic manteniendo pulsada la tecla Control en la imagen que desea convertir a texto y, a continuación, haga clic en OCR en el menú que aparece.
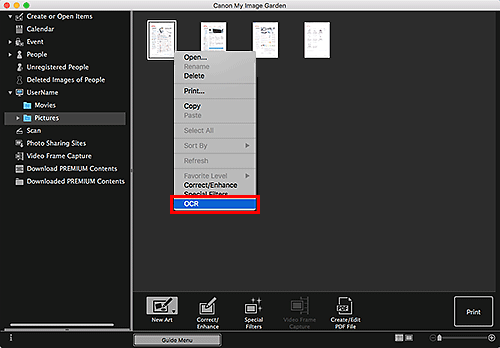
Se inicia TextEdit (incluido en Mac OS) y se muestra el texto para editarlo.
 Nota
Nota- Sólo el texto que esté escrito en los idiomas que se pueden seleccionar en la ficha Configuración avanzada (Advanced Settings) del cuadro de diálogo Preferencias (Preferences) se puede extraer en TextEdit (incluido en Mac OS). Haga clic en Configuración... (Settings...) en la ficha Configuración avanzada y especifique el idioma en función del idioma del documento que se vaya a escanear.
Cuando se escanean varios documentos, se puede reunir el texto extraído en un archivo. -
El texto que se muestra en TextEdit (incluido en Mac OS) es orientativo únicamente. El texto de las imágenes de los siguientes tipos de documentos es posible que no se detecte correctamente.
- Documentos con texto cuyo tamaño de fuente no se incluya en el intervalo de 8 a 40 puntos (a 300 ppp)
- Documentos torcidos
- Documentos colocados con la parte superior hacia abajo o documentos con texto con una orientación incorrecta (caracteres girados)
- Documentos que incluyan fuentes especiales, efectos, cursiva o texto escrito a mano
- Documentos con un espaciado de línea estrecho
- Documentos con colores en el fondo del texto
- Documentos escritos en varios idiomas
- Sólo el texto que esté escrito en los idiomas que se pueden seleccionar en la ficha Configuración avanzada (Advanced Settings) del cuadro de diálogo Preferencias (Preferences) se puede extraer en TextEdit (incluido en Mac OS). Haga clic en Configuración... (Settings...) en la ficha Configuración avanzada y especifique el idioma en función del idioma del documento que se vaya a escanear.
